LeNet
LeNet是由LeCun等人最早的一批卷积神经网络,该系列网络结构最早是1989年设计出来的,目前常说的LeNet默认是指LeNet5,是1998年设计出来的网络。LeNet主要用在图像分类和手写数字识别应用上。后面说到的LeNet默认指代LeNet5。
网络结构
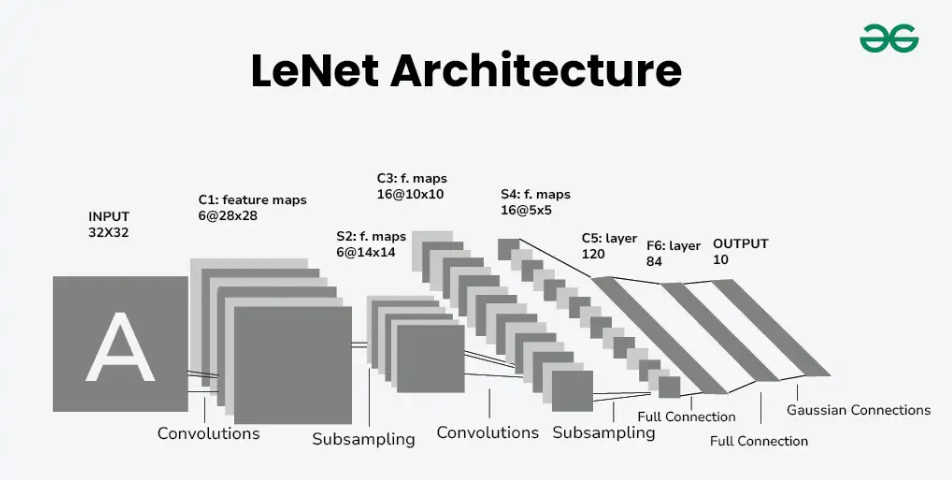
LeNet网络结构如上图所示。该结构除去输入层包含7层。具体如下:
1、输入层(Input)
- 输入大小:输入层为32 * 32像素大小,因此输入的图像需要先转换为黑白单通道的图片。
2、层1:卷积层(C1)
- 使用6个特征层,每个特征层为5 * 5形状的卷积核,最终形成6通道,形状为28 * 28的特征图。
- 参数量计算:channel:6 *(kernel:5 * 5 + bias:1) = 156
- 连接数:channel:6 * (kernel:5 * 5 + bias:1) * out:28 * 28 = 122304
3、层2:下采样层(S2)
- 四个相邻的像素相加,之后与一个可训练参数相乘,加上bias,用sigmoid函数激活。
- 参数量:channel:6 * (kernel:1 * 1 + bias:1) = 12
- 连接数:channel:6 * (kernel:2 * 2 + bias:1)*(out:14 * 14)= 5880
4、层3:卷积层(C3)
- C3与S2并非全连接,输出通道为16,输入通道6,具体的连接关系如下:C3的前6个特征图以S2中3个相邻的特征图子集为输入。接下来6个特征图以S2中4个相邻特征图子集为输入。然后的3个以不相邻的4个特征图子集为输入。最后一个将S2中所有特征图为输入。如下图所示。

- 参数量:6*(3 * 5 * 5 + 1)+ 6 * (4 * 5 * 5 + 1)+3 * (4 * 5 * 5 + 1)+1 * (6 * 5 * 5 + 1)= 1516
- 连接数:10 * 10 * 1516 = 151600
5、层4:下采样层(S4)
- 采样区域为2 * 2,每个采样区域四个值相加,乘上一个可训练的参数,加上bias,用sigmoid激活。
- 参数量:16 * (1 + 1) = 32
- 连接数:(2 * 2 + 1) * 16 * (5 * 5) = 2000
6、层5:卷积层(C5)
- 卷积核为5 * 5,卷积核数量为120,每一个卷积核都与S4中的所有通道相连接。
- 参数量:(5 * 5 * 16 + 1) * 120 = 48120
- 连接数:48120 * 1 * 1 = 48120
7、层6:全连接层(F6)
- 计算输入向量和权重向量之间的点积,再加上一个偏置,结果通过sigmoid函数
- 参数量:84 * (120 + 1)= 10164
- 连接数:10164
8、层7:全连接层(F7)
- 与上一层类似,最后一步是Gaussian Connections,采用了RBF函数(即径向欧式距离函数),计算输入向量和参数向量之间的欧式距离。目前已经被Softmax取代。
- 参数量:10 * (84 + 1) = 850
- 连接数:850
参考文章
- LeNet — PaddleEdu documentation
- LeNet-5识别手写数字 – tianhaoo
- https://www.geeksforgeeks.org/lenet-5-architecture/
AlexNet
LeNet在小数据集上具有比较好的效果,但是面对更大规模的数据集性能受到限制,为此Alex Krizhevsky等人在2012年提出了一种新的网络结构,也就是接下来要介绍的AlexNet。AlexNet在当时是第一个在ILSVRC-2012挑战赛上取得显著成功的深度学习模型,竞赛中获得了top-5测试的15.3%error rate(top-5 error rate:使用预测结果的Top-5(分类结果标签的前五个)与正确结果进行对比,如果五个之中有一个正确那么就认为分类器预测结果正确),远超第二名。
网络结构
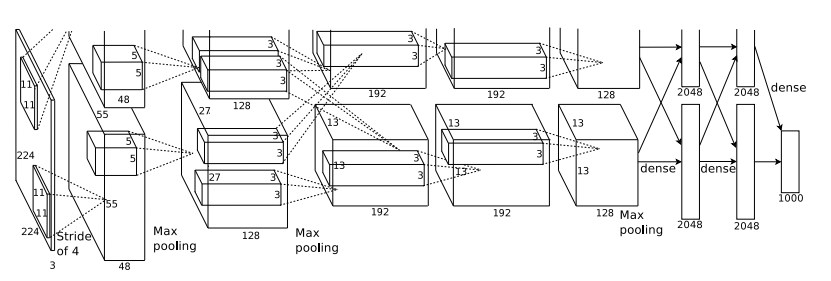
AlexNet网络官方论文结构图如上所示。简化后的结构如下图所示:
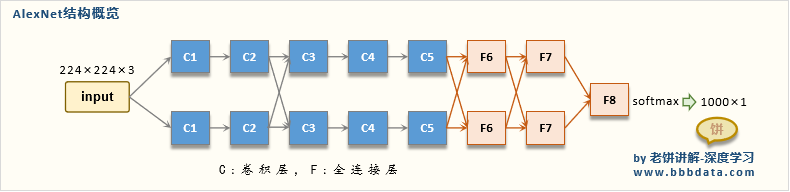
输入相比于LetNet的单通道输入,变成了三通道输入,意味着能够直接对三通道RGB彩色图片进行识别。其输入是224 * 224 * 3的图片,最终输出为1 * 1000的向量,为什么是1000,因为是以ImageNet作为训练集训练的🐸。
根据结构简图可以知道,AlexNet整体是一个双分支的结构,每个分支都由5个卷积层加2个全连接层构成,分支中有个别层会进行数据的交换。最后通过全连接层和softmax将两个分支进行合并。
各层的参数量以及运算演示,这里找到了写的比较好的一篇文章👍。
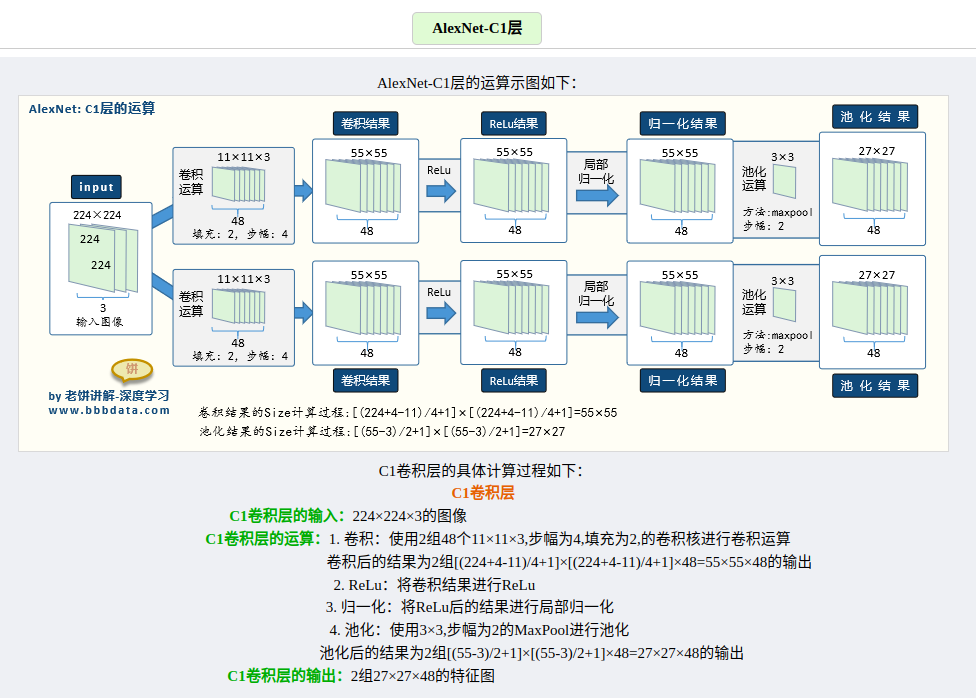
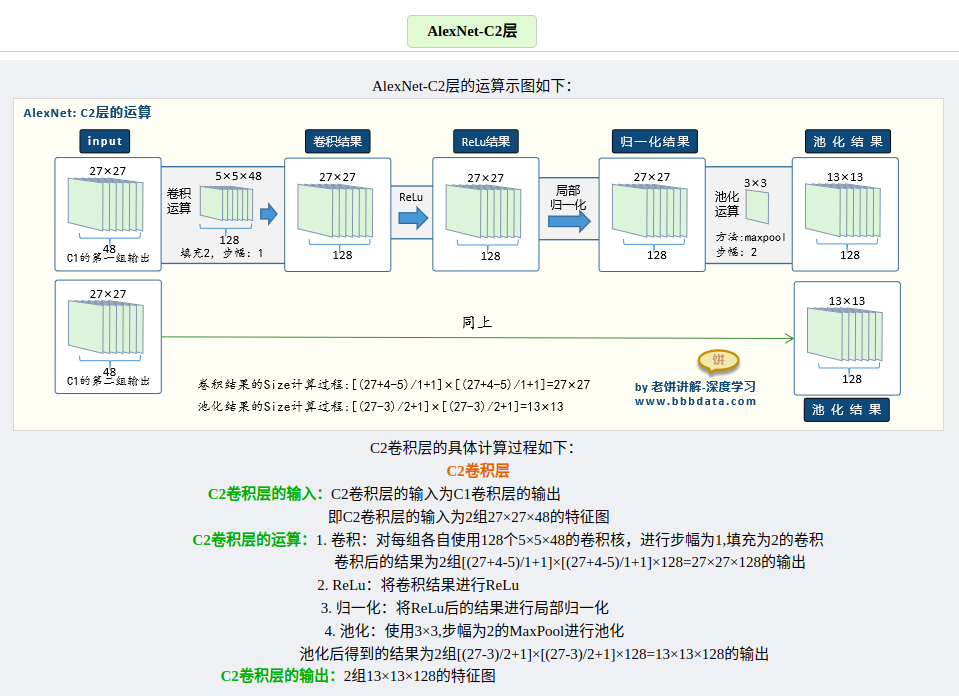
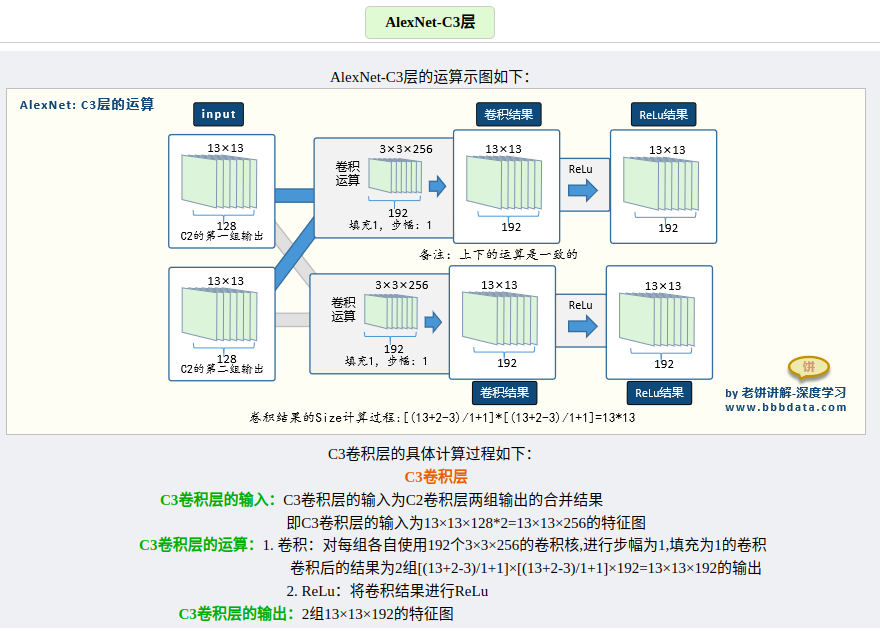
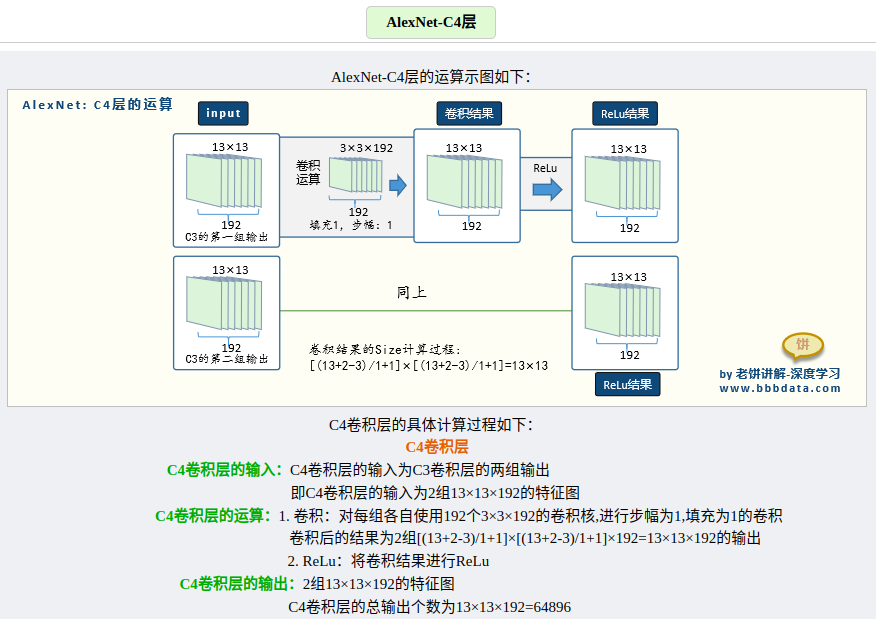

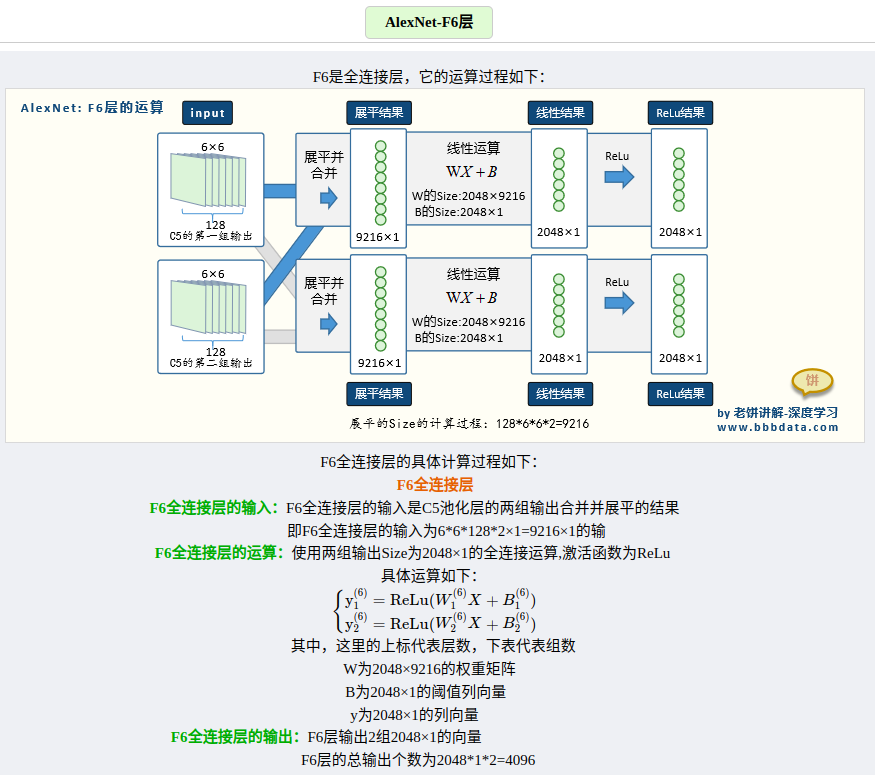
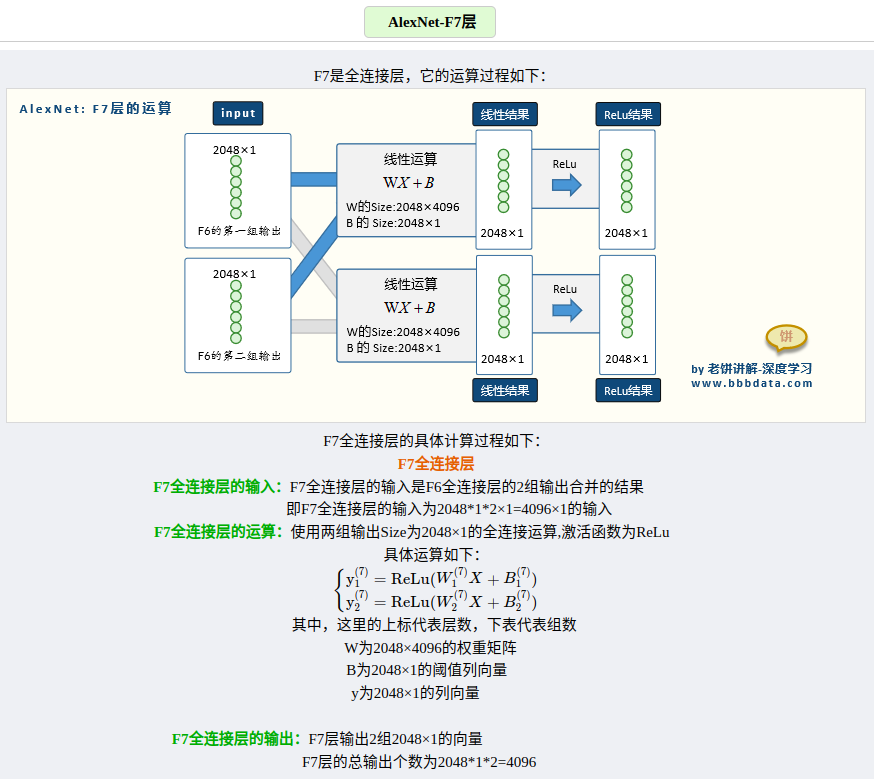
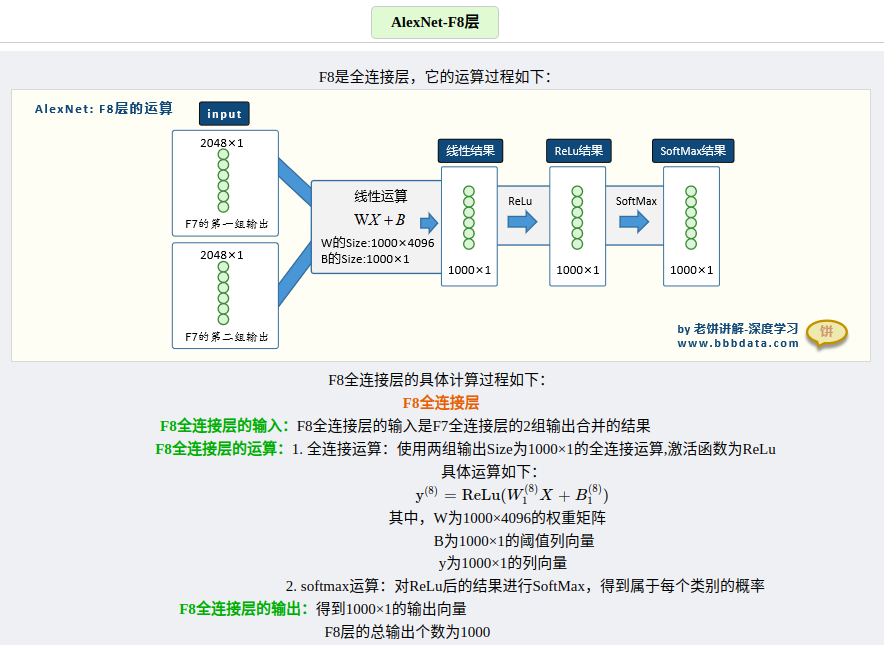
参考文章
VGGNet
VGGNet是2014年牛津大学提出的,该工作证明了增加网络的深度能够在一定程度上影响网络最终的性能。VGGNet有两种结构:VGG16和VGG19,两者除了网络深度不一样,本质没有区别。此外,VGGNet将传统的大卷积换成了小卷积核,开启了小卷积的应用之路。
- 为什么不用大卷积?
1、在感受野相同的情况下,小卷积核的参数量更加小。
举个例子说明(省略bias,因为不影响分析结果):下图最底层为5*5的特征图,如果我们使用5*5的卷积核,步长为1,那么最终得到的特征图为1*1的特征图,在这个过程中,参数量为:5*5=25。那么如果采用3*3的卷积核,最终让特征图变成1*1,需要怎么做?可以用两个3*3的卷积核,第一次卷积之后得到3*3特征图,在进行一次卷积得到1*1的特征图,在这个过程中,第一次卷积参数量为:3*3=9,第二次卷积参数量为:3*3=9,相加最终为18<25。因此用小卷积核虽然核的数量变多,但是最终计算参数量却下降了。
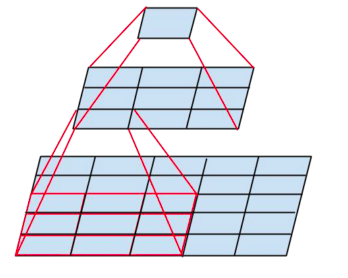
2、三层小卷积核的拟合能力更强
由于卷积层后会跟随一个非线性激活函数(不妨设为ReLu),单个大卷积层的输出对原始X进行了一次非线性转换:
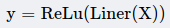
而三个小卷积层的输出对原始X进行了三次非线性转换:
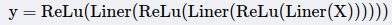
明显地,三层结构拥有三次非线性变换,它的拟合能力更强
网络结构
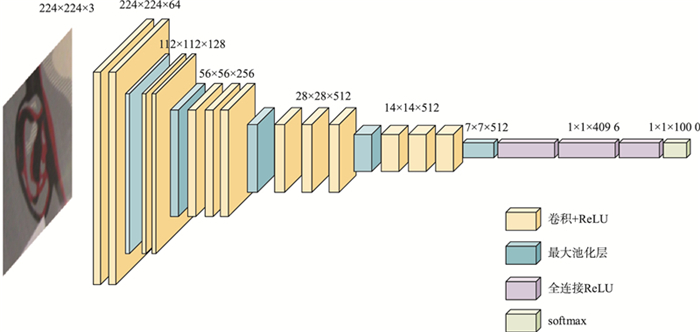
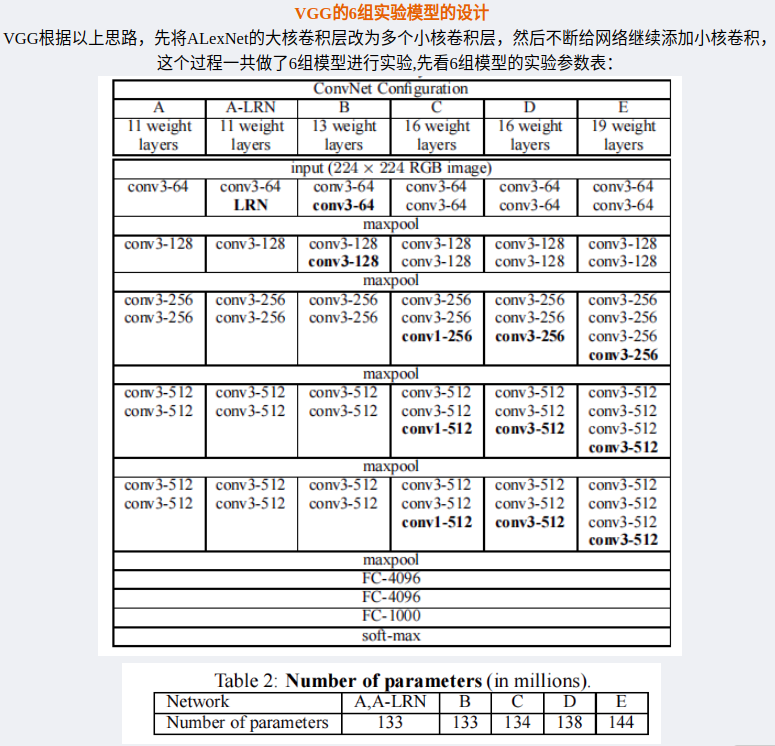
1. VGGNet的小核亮点
可以看到,从模型A到模型E,模型的深度由11层到19层,但参数却没有过多的增长,所以用小核层换大核层确实是个很好的方法。
2. 该关注VGGNet的哪些模型
D和E又根据层数,被后人称称为VGG16和VGG19,也就是说,除了D和E,其它的只是VGG实验品,不用过于关注。
VGGNet实验中的一些配置解释
1、为什么使用形式的1×1卷积层
在VGGNet的实验中,时不时会加入一些核Size为1×1的卷积层。为什么要加入这些1×1的卷积层进行尝试呢?1×1的卷积层的意义是什么?由于1×1的卷积核每个通道只有1个元素,所以它相当于将之前图像的各个通道加权合并为一个新的图像。
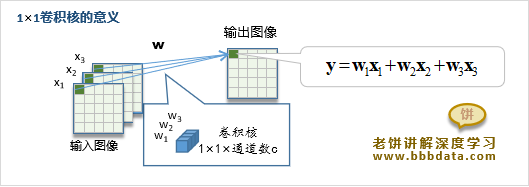
注意到实验中所用的1×1卷积核个数与输入通道一致,并且随后会被ReLu。因此整层的意义是将原图像的n个通道线性合并成新的n个通道,并进行非线性ReLu影射。总的来说,1×1卷积层的意义就是将原图像进行一次Size不变的非线性层转换。备注:1×1卷积层只是模型C的一种尝试,VGG16、19中并不使用。
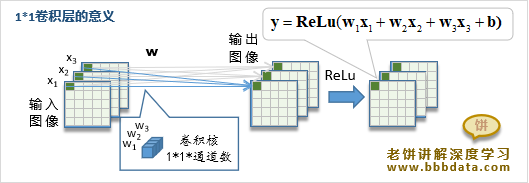
2、关于卷积输出通道个数的设置
VGGNet中卷积的输出通道个数的设置是有规律的,对于每一个大层,卷积输出通道个数翻倍递增,以64为初始值,512为最大值。
参考文章
- https://www.bbbdata.com/text/827
- 两个连续的3×3卷积核的感受野与一个5×5卷积核的感受野相同
- http://xk.sia.xml-data.org/XXYKZ/html/1630988216103-1322756001.htm
GooLeNet
GooLeNet是google团队在2014年提出的深度神经网络模型,并且在当年的ImageNet挑战赛中获得了冠军。为了向LeNet致敬,团队将模型取名为GooLeNet。Respect!!!
受到NiN(Net in Net)网络的影响,GooLeNet做了更加大胆的网络结构尝试,急剧减小网络参数量,参数量只有500万个,AlexNet约为GooLeNet的12倍,VGGNet约为GooLeNet的36倍,这得益于Inception的影响,随着进一步研究,google团队还推出了v2、v3、v4版本。网络上说,Inception可能得名于电影《盗梦空间》(Inception),因为电影中的一句话“我们需要走得更深”(“We need to go deeper”)。
网络结构
完整的网络结构较大,因此本文只关注模型核心模块Inception。
Inception v1
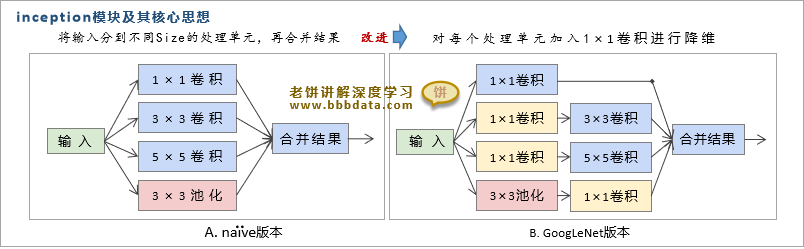
Inception模块的原始版本如图A所示,它用多个模块(卷积、池化等等)对输入进行处理,再将处理结果合并,传出下一层。从可解释角度可以理解为:
- 从生物角度,可以将它理解为,综合粗看、细看的结果作为输出。
- 从数学角度来说,用不同的过滤器去捕获特征,这样可以使特征多样化。
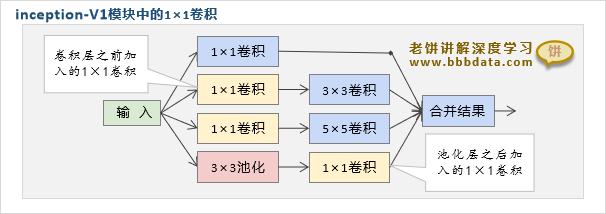
Inception模块在卷积前和池化后都加入了1×1卷积模块,为什么GoogLeNet要加入这些1×1卷积呢?
1、1×1卷积相当于将输入的各个通道进行线性综合成一个新的输出
如下图所示。例如输入是100个通道,那么10通道的1×1卷积,就相当于将100个输入通道线性转换为10个输出通道。通俗来说,1×1的卷积就是将整块通道视为一个单元,进行线性合并。
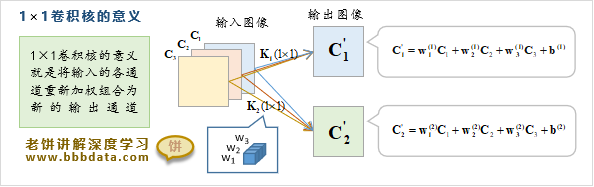
- 输入为100通道,用10通道的卷积核转换成10通道的输出,怎么理解?
解:以下图为例,使用输入通道数为3、输出通道数为2的1×1卷积核的互相关计算。输入和输出具有相同的高和宽,通道数量减少。

2、卷积层之前先进行1×1卷积,主要是为了进行降维,减少参数的个数
例如,输入通道为128,输出通道我们希望也是256,如果直接用5×5的卷积,那么参数个数为128*5*5*256+256=819456,但如果先通过1×1卷积,再用5×5卷积,那么参数个数会被1×1卷积的输出通道数控制我们可以先设定1×1卷积的输出通道数为32,那么参数个数为(128*1*1*32+32)+(32*5*5*256+256)=209184,最终的输出通道仍为256,但参数明显就减少了许多总的来说,就是参数个数受输入通道和输出通道个数的影响,而先利用1×1卷积对输入通道进行降维,再传给5×5的卷积,可以减少5×5卷积核的参数。
3、池化层之后附加一个1×1的卷积层,主要是为了减少输出通道个数
由于池化运算,输入有多少个通道,输出就有多少个通道,如果没有进行降维,那么池化层与其它层的输出通道数之和,一定大于输入通道,这样会导致在多个inception模块相连时,输出通道数会越来越多。所以在池化层之后 附加一个1×1的卷积层,以控制整体的输出通道个数。
Inception模块的本质
1、通过合理的稀疏结构来降低模型的复杂度,以此避免过拟合
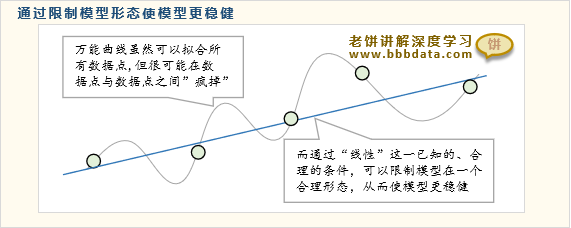
如果我们用一个万能函数拟合一些数据点,由于万能函数能揉出任意形状,所以揉出来的曲线即使拟合了所有数据点,但它在非数据点处可能会“疯掉”,这就是过拟合了。
但如果我们知道数据点是线性关系,从一开始就限定模型结构是线性,那么模型不仅简单,而且由于它只能是线性曲线,它不可能在非数据点处“疯掉”,这就是通过已知的“信息”来限制模型,从而加强模型形态的合理性,Inception就是这样,利用”综合粗看、细看的结果作为输出”这个信息来限制模型的形态。总的来说,Inception就是设定一个合理的稀疏结构,替代原本的全连接,合理简化模型,一方面避免模型过拟合,另一方面,稀疏结构也比全连接的参数更少,计算量更少。
2、加入1*1卷积进行降维,防止计算量过于庞大
计算量过大会令训练速度变慢,Inception模块过通1*1卷积,调控参数的个数,减少计算量,使Inception模块得以投入实际使用。
参考文章
- https://zh.d2l.ai/chapter_convolutional-modern/googlenet.html
- https://www.bbbdata.com/text/793
- http://zh.gluon.ai/chapter_convolutional-neural-networks/channels.html